********************오늘 공부하면서 알아낸 사실들*********************
<DNN(Deep Neural Network)>
깊은 신경망을 의미, 여러개의 은닉층으로 구성되어 있다. 의미한다.
주로 구조적인 데이터, 수치적인 데이터 처리에 사용됨(일반적인 딥러닝 모델을 의미)
<CNN(Convolution Neural Network)>
합성곱 신경망, 합성곱층과 풀링층이 존재한다.
이미지같은 2D 데이터를 처리하는데 특화됨
<Data Scaling>
머신러닝,딥러닝에서 데이터를 전처리해 입력데이터의 스케일을 조정해준다.
예시: Min Max Scaling: 데이터 값을 0~1사이로 정규화해서 조정해준다.
<RNN(Recurrent Neural Network, 순환 신경망)>
시계열 데이터(시퀀스 데이터)처럼 순서가 존재하는 데이터를 처리시 적합한 인공신경망 구조
다른 신경망과는 다르게 입력과 출력을 시퀀스 단위로 처리가 가능(자연어, 음성인식, 기계 번역등 처리시 좋다.)
주요 특징은 순환적인 구조를 가지고 있다(과거 출력이 현재의 입력으로 사용, 인간지네같다)
RNN은 시퀀스 데이터의 내부의존성을 잘 파악하고 이전 정보를 활용하여 다음 정보를 예측하는데 우수한 성능을 보인다.
but 기울기 소실 문제가 발생 이를 위해서 LSTM이 제안된다
<LSTM(Long Short-Term Memory, 장단기 메모리)>
순환신경망의 한 종류, 시계열 데이터 OR 자연어 리처럼 순서가 존재하는 데이터 처리시 사용, 기존 RNN(순환 신경망)의 문제점인 기울기 소실(Vanishing Gradient)문제를 해결하기 위해서 탄생
RNN은 시퀀스데이터의 특징을 잘 캡쳐한다. BUT 데이터가 길어질수록(출력과 먼 위치에 있는 정보) 기울기가 소실되는 문제가 발생, 이를 기억셀(memory cell)과 게이트(gate) 메커니즘을 도입해 해결한다.
# 기울기 소실: 딥러닝 모델에서 발생하는 문제중 하나(주로 깊은 신경망(DNN)에서 발생),
# 시퀀스 데이터: 순서나 시간의 개념이 있는 데이터를 의미(이전 원소와의 관련성이 존재한다)
<시계열 데이터>
일정한 시간 간격으로 측정된 데이터의 수열을 의미, 시간에 따라 변화하는 경향성과 패턴을 가지고 있다. 주식가격, 기온변화, 판매량 추이 등
<시계열 DB>
시간순서로 정렬된 시계열 데이터를 저장하고 관리하는 DB 시스템이다. 주로 시간에 따라 변화하는 데이터를 저장 및 조회시 사용한다.
<기울기 소실(Gradient Vanishing)>
역전파 알고리즘을 통해 신경망을 학습할 때 입력 데이터로부터 출력 쪽으로 오차를 역전파하여 가중치를 조정하는데, 이 과정에서 기울기(gradient)가 점점 작아져서 가중치 갱신이 제대로 이루어지지 않는 현상을 말합니다. 이로 인해 모델이 학습을 제대로 수행하지 못하고 성능이 저하될 수 있습니다.
<오차역전파(Backpropagation)>
가중치와 편향 값을 조정하기 위해서 사용되는 학습 알고리즘, 인공신경망은 입력 데이터에 대한 출력을 예측시 사용, 이때 신경망의 가중치화 편향이 올바르게 조정되어야 예측을 수행할수 있다. 역전파 알고리즘은 이러한 가중치와 편향을 효율적으로 조정하는 방법 중 하나이다.
오차역전파는 다음과 같은 과정으로 이루어집니다:
1. 순전파: 입력 데이터가 신경망을 통과하여 출력을 예측합니다. 이때 가중치와 편향이 사용됩니다.
2. 손실 함수 계산: 예측된 출력과 실제 타겟 값 간의 차이를 계산하여 손실 함수 값을 얻습니다. 이 손실 함수는 예측의 오차를 측정하는데 사용됩니다.
3. 역전파: 손실 함수 값의 기울기를 계산하여 출력 층부터 입력 층까지 거꾸로 전파합니다. 이때 각 층의 가중치와 편향이 오차에 얼마나 기여했는지를 계산합니다.
4. 가중치 및 편향 업데이트: 역전파된 기울기를 사용하여 가중치와 편향을 조정합니다. 이렇게 하면 예측 오차가 최소화되는 방향으로 신경망이 학습되도록 됩니다.
<원핫인코딩>
텍스트나 범주형 데이터를 숫자로 변환시 사용
원핫 인코딩을 적용하면 다음과 같이 변환됩니다.
사과: [1, 0, 0]
바나나: [0, 1, 0]
오렌지: [0, 0, 1]
각 카테고리가 고유한 숫자로 매핑되어 머신러닝 모델에 입력으로 사용이 가능하다
<API>
특정 기능을 제공하는 인터페이스(인터페이스= 규칙과 규약, 다른 시스템이나 컴폰넌트들이 서로 통신학소 상호작용하는 방법을 정의한 것)
<활성화함수 (Activation Function, 퍼셉트론의 출력값을 결정하는 비선형함수,다음 레이어 입력범위 변환기)>
각 층의 출력값을 다음 층의 입력값 형태에 맞게 변환하는 함수
활성화 함수는 인공 신경망에서 비선형성을 도입하는 중요한 요소입니다.
비선형성이란 함수의 출력이 입력에 대해 선형적으로 변하지 않는 것을 의미합니다.(일정하다는 의미 이다.)
1. 시그모이드 함수: 다음층으로 넘기는 입력범위를 0~1사이의 실수값으로 압축시킨다.()

2. 하이퍼볼릭 탄젠트 함수: 다음층으로 넘기는 입력범위를 [-1,1]로 제한한다

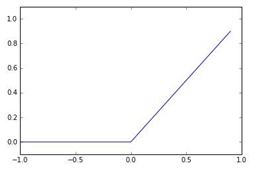

6. 소프트맥스 함수: 다중 클래스 분류 문제에서 사용(아이리스 품종 예측), 각 클래스에 대한 확률 분포를 출력, 출력 값들의 합이 1이 되도록 변환하여 클래스에 속할 확률을 표현함(확률분포 형태로 바꿔줌)
7. ELU 함수: 입력값이 음수인 경우에 지수함수를 사용하여 출력값을 조정하는 형태이다. relu는 0이하의 값은 모두 0이지만, ELU는 음수를 조금 더 부드럽게 지수적으로 하강하는 형태를 보인다.(마지노선은 –a)

딥러닝 모델에서 활성화 함수는 각 뉴런의 출력을 결정하는 역할을 하므로, 올바른 활성화 함수의 선택은 모델의 성능에 큰 영향을 미칠 수 있습니다. "Mish" 활성화 함수는 기존의 함수들과 비교하여 더 나은 성능을 보여줄 수 있으며, 특히 이미지 분류 및 객체 검출 등의 태스크에서 잘 작동할 수 있습니다.

<비선형 함수>
곡선, 혹은 불규칙한 형태 (직선으로 쭉 상승하거나 하강하는 형태를 방지한다.) 입력과 출력간의 관계가 복잡한 형태를 가지는 것을 의미한다.
<SMAPE(Symmetric Mean Absolute Percentage Error)>
'알아두면좋은IT상식' 카테고리의 다른 글
| CPD(Change Point Detection, 변화 지점 탐지)란 무엇인가?~ (0) | 2023.12.24 |
|---|---|
| [CS] 디자인 패턴과 프로그래밍 패러다임 part 1 (2) | 2023.10.26 |
| [Git&Github] 깃이란 무엇인가 그리고 깃허브는 어떻게 쓰는건가? part 2 (0) | 2023.07.07 |
| [Git&Github] 깃이란 무엇인가 그리고 깃허브는 어떻게 쓰는건가? part 1 (0) | 2023.07.06 |
| [딥러닝] YOLO(You Only Look Once) 객체 탐색 알고리즘 (0) | 2023.07.05 |



